C#で高速なプログラムにする際のお供な構造体ですが、構造体を使わないほうがいい場面・条件もあります。
その一つに”サイズが16バイト未満であること”があります。この16バイトという数字の根拠は明確にはわかりませんが、構造体の特性上よく値コピーが発生するのでサイズが大きければ大きいほど値コピーのコストが高まるということからある程度のサイズまでのものがいいというのは想像つくと思います。
そしてこの値コピーが発生する個所としてよくあるのがメソッド呼び出しの引数に構造体を渡したときなのですが、C# 7.2で追加されたin引数/ref readonlyを使うと読み取り専用参照として渡せるので値コピーを抑制することができるようになりました。
そこで「値コピーがつらくてBig Size Structが使えないなら値コピーしなければいいじゃん」(以下in引数戦略)という疑問が生まれます。
実際に測ってみた
値コピーありのメソッド呼び出しとin引数で参照を渡すメソッド呼び出しの相対的な速度比を計測してみることにします。
利用するのはベンチマークのお供なBenchmarkDotNetです。計測実行環境としては.NET Frameworkと最近パフォーマンスが向上した.NET Coreです。(もちろんのことながらホストマシンはWindowsです)
計測対象はこのような感じの構造体です
readonly struct Size16
{
public readonly int A, B, C, D;
}
readonly struct Size32
{
public readonly Size16 A, B;
}
readonly struct Size64
{
public readonly Size32 A, B;
}
Size32からフィールド宣言がめんどくさくて定義済みの構造体を利用していますが、計測したいのはサイズごとの相対比なので問題ないでしょう。
また、計測メソッドは下のような感じです。
[Benchmark]
public int Size32NormalCall()
{
Size32 v = default;
return size32(v);
}
[Benchmark]
public int Size32InCall()
{
Size32 v = default;
return size32(in v);
}
[MethodImpl(MethodImplOptions.NoInlining)]
private int size32(Size32 size32)
{
return size32.A.A;
}
[MethodImpl(MethodImplOptions.NoInlining)]
private int size32(in Size32 size32)
{
return size32.A.A;
}
最適化逃れのためにいろいろ無駄なことをしていたりインライン化抑制の属性を付けていたりします。
これで期待通りに変な最適化さえ起きていなければ、値コピーとin引数の相対的な速度比が求めれるはずです。
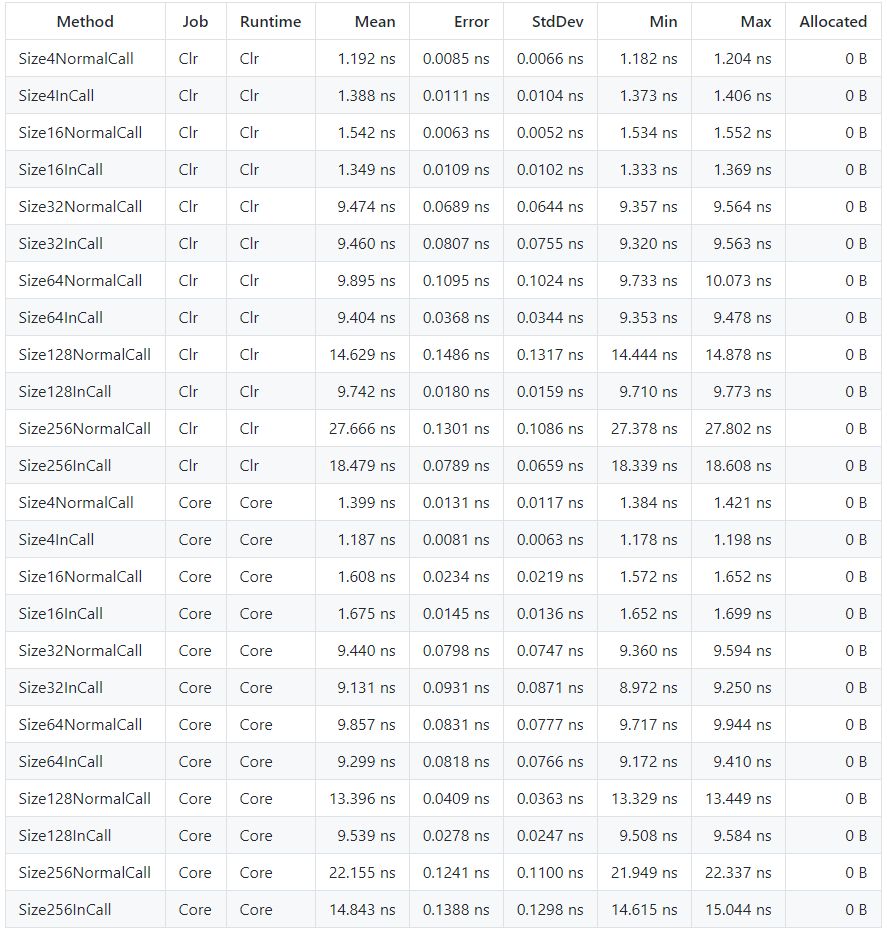
これをSize4, 16, 32, 64, 128, 256で実行した結果が下の表になります、また全体のソースコードはgistで公開しています。
BenchmarkDotNet=v0.10.14, OS=Windows 10.0.16299.492 (1709/FallCreatorsUpdate/Redstone3)
Intel Core i7-6700 CPU 3.40GHz (Skylake), 1 CPU, 8 logical and 4 physical cores
Frequency=3328127 Hz, Resolution=300.4693 ns, Timer=TSC
.NET Core SDK=2.1.300
[Host] : .NET Core 2.1.0 (CoreCLR 4.6.26515.07, CoreFX 4.6.26515.06), 64bit RyuJIT
Clr : .NET Framework 4.7.1 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.2671.0
Core : .NET Core 2.1.0 (CoreCLR 4.6.26515.07, CoreFX 4.6.26515.06), 64bit RyuJIT
また、値コピーを100としたときのin引数との速度差(in引数の速度/値コピーの速度*100で求められるもの)のグラフは次のような感じです。
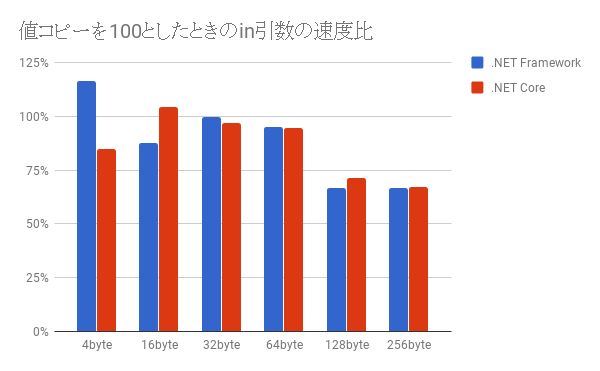
16byteまではin引数のほうが遅い場面もあり、32byteと64byte付近ではどちらともあまり変わらず、128byteまで行くとin引数のほうが数割早いと読み取れます。
これだけを見るならばBig Size Structはin引数戦略で勝つると思っちゃいますが、これはあくまでメソッド呼び出し時の値コピーを抑制しただけです。
値コピーする場面は他にもある
防衛的コピー
ufcppさんが++C++; // 未確認飛行 C - readonlyの注意点 - readonly struct によるコピー回避で述べられてるように、構造体で定義されているメソッドを呼び出してしまうと防衛的にコピーしてしまうようです。これは同じくC# 7.2で追加されたreadonly structにすることで防げます。
スタックからヒープへのコピー
構造体はローカル変数ではスタックに確保されますが、ローカル変数の場合ではどこに属しているかで確保される場所が変わります。classのインスタンス変数であるとヒープに確保されます。ローカル変数からclassのインスタンス変数に代入すると値コピーが走ってしまいます。
ヒープへのコピーをさせないという制約を持たせるならば、C# 7.2で追加されたref構造体(意味合いとしてはstackonly構造体)にすることで完全にスタック上のみの構造体にすることもできます。ただ、非常に扱いにくくなるので使用するかは考えどころですが。
また、ボックス化するときもヒープへ確保されるので値コピーが発生してしまいます。
構造体をインターフェースの型で確保するなどしてしまうとボックス化してしまうので値コピーが発生してしまいます。
こちらもref構造体で縛ることができます。
代入時のコピー
構造体(値型)の変数を他の変数へ代入してやると値コピーが発生してしまいます。この特性はC#erなら暗黙的に理解できていると思います。
int a = 10;
int b = a;
a = 20;
Console.WriteLine(b);
このようなコードを実行すると10が出力されるのはint b = a;で値コピーが発生しているからです。
これはrefをとってやると値コピーせずに代入できます。
int a = 10;
ref int b = ref a;
a = 20;
Console.WriteLine(b);
こちらのコードを実行すると20が出力されます。
C# 7.3でref再代入ができるようになったので、値コピーを走らせずにローカル変数を使いまわすことはできるようになったのではないかなと思います。
最終的なin引数戦略
- readonly structを使う
- in引数ref, out引数を使う
- ref変数やref再代入で値コピーを減らす
- なるべくヒープ上に確保しない
- ref structを使う
- ヒープに確保される仕様を理解し適切に扱う
以上のような感じでしょうか、もはやポインターを安全にした感じのようなものですね。
(実際に安全に扱えるようにした機構だからしょうがないか………)
Big Size Structのスタック確保とclassでのヒープ確保のベンチマークとか測ってなかったり(おそらくスタックのほうが早いはず)、C#の仕様をまだまだ理解しきれてないアマチュアC#erですが、間違い・考慮漏れなどやマサカリなどあればどしどしコメントに投下してくださいm(__)m
コメントいただいたことないので、はたしてコメント機能が正常に動作してるかわかりませんが、Twitterのほうでも受け付けますのでぜひともお願いしますm(__)m
(in引数戦略と言ったが最終的にはref戦略になってるような気がする)